Jinhee Kim
PhD Student @ Duke ECE

first.last at duke.edu
Hi! I’m a PhD student in the CEI Group at Duke ECE, where I’m fortunate to be advised by Prof. Yiran Chen. Before coming to Duke, I was part of the IRIS Lab at Sungkyunkwan University.
My research interests include Efficient Machine Learning, Adaptive Deep Learning Inference, and Model Quantization.
selected publications
news
| Oct 10, 2025 | I’m also very grateful to receive the NeurIPS 2025 Scholar Award. |
|---|---|
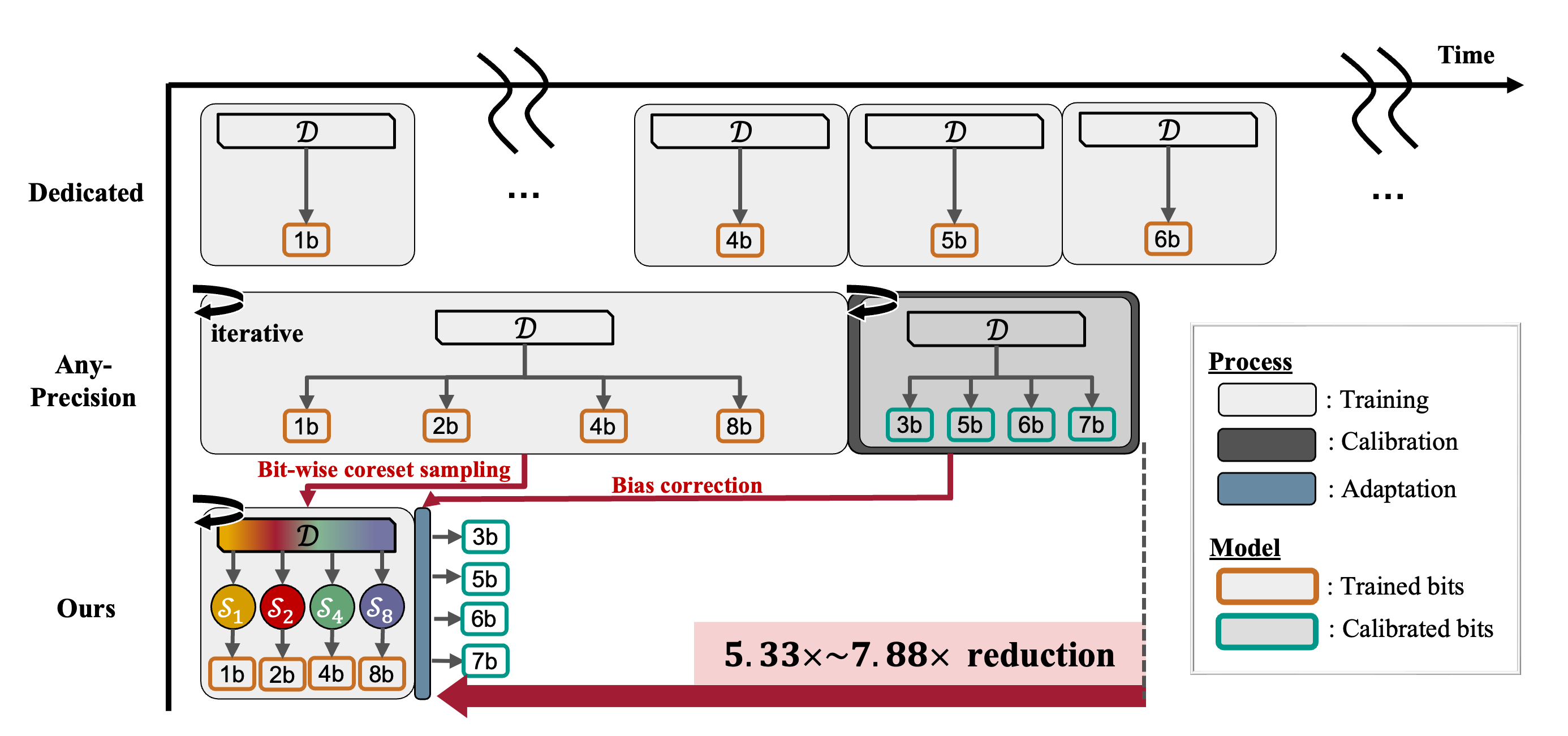
| Sep 18, 2025 | EMQNet ↵ Project code is accepted at NeurIPS 2025. EMQNet reduces the training time of multi-bit networks by up to ~7.88x! |
| Aug 30, 2025 | Very excited to join Duke ECE as a PhD student in Fall ‘25! |
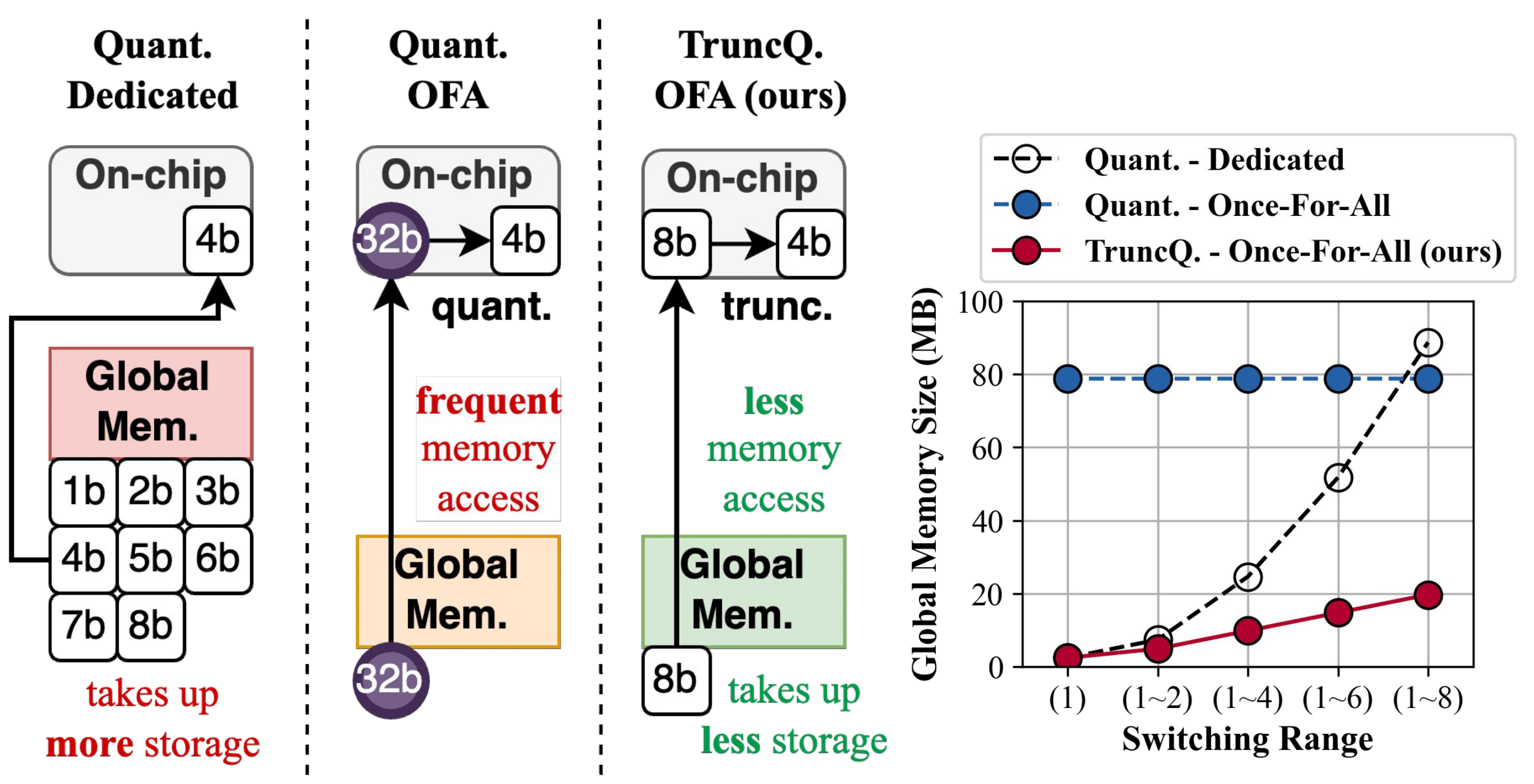
| May 19, 2025 | TruncQuant ↵ Project code is accepted at ISLPED 2025. TruncQuant enables low-bit inference via simple truncation (bit-shifting) of LSBs. No quantization function, no floating-point operations, and no memory movement—just lightweight integer logic! |
| Jul 18, 2024 | Honored to receive the top AI Undergraduate Paper Award at the Summer Annual Conference of IEIE, and the Cross-disciplinary Research Award at SKKU’s research competition. ↵link |