Attention Is All You Need
2023-10-02
Keywords: #Transformer
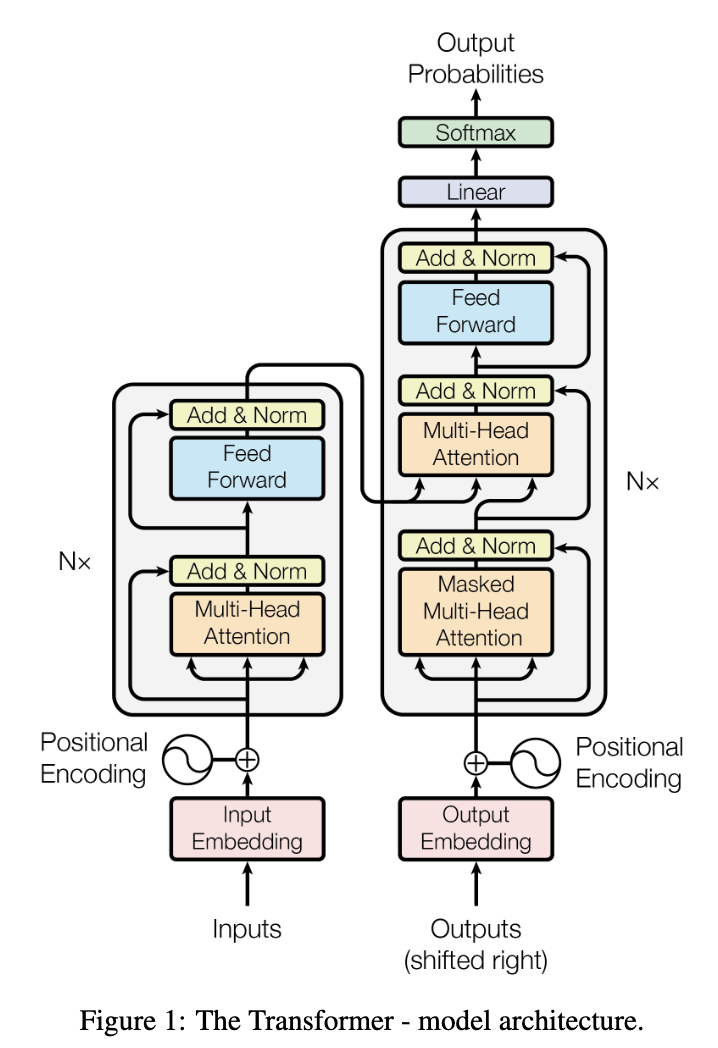
3. Model Architecture
3.1 Encoder and Decoder Stacks
- Encoder
- Multi-head self-attention
- Residual connection + Layer Normalization → $\text{LayerNorm(x+Sublayer(x))}$
- Fully connected feed-forward
- Decoder
- Outputs (shifted right) + Masked Multi-head attention: Ensures that the predictions for position $i$ can depend only on the known outputs at positions less than $i$.
- Multi-head attention
- Fully connected feed-forward
3.2 Attention
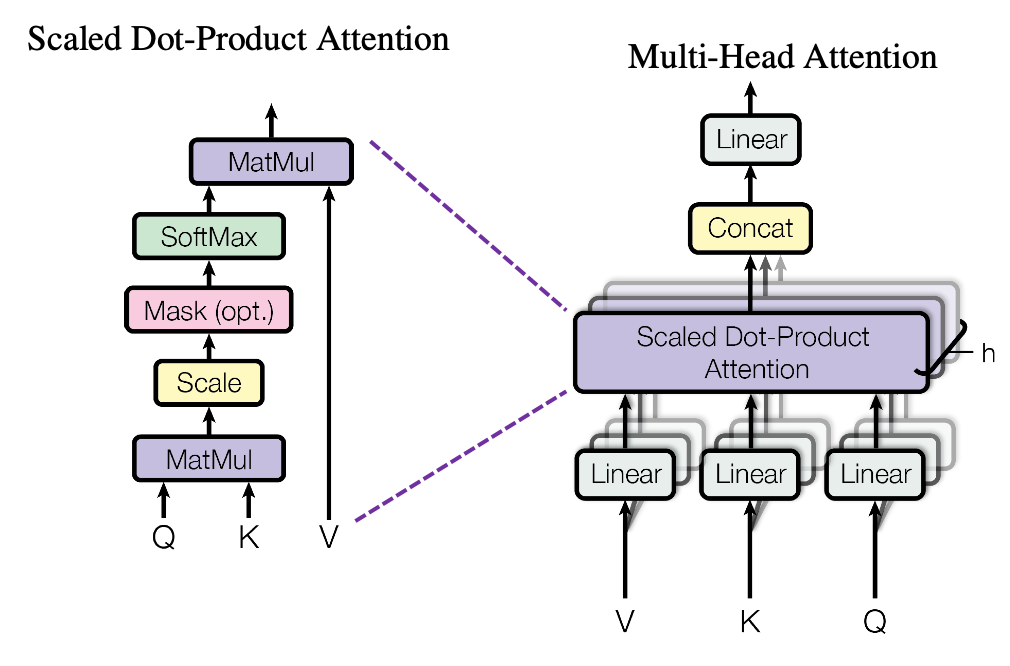
⚔️ Intuition behind Query (Q), Key (K), Value (V)
- Find the relations between each token in “I am a teacher.”
⚔️ Scaled Dot-Product Attention
⚔️ Multi-Head Attention
⚔️ Applications of Attention in our Model
- Encoder-Decoder Attention
- Q comes from prev. decoder layer, while K and V come from the output of the encoder.
- This allows every position in the decoder to attend over all positions in the input sequence.
- Encoder Self-Attention
- K, V, Q come from the same place- output of the previous layer in the encoder.
- Each position in the encoder can attend to all positions in the previous layer.
- Decoder Self-Attention
- Each position in the decoder to attend to all positions in the decoder up to and including that position.
- Illegal connections are masked out to $-\inf$ to prevent leftward information flow → Preserve auto-regressive property
3.3 Position-wise Feed-Forward Networks
- A fully connected feed-forward network is applied to each position separately and identically.
- Two linear transformations with a RELU activation in between: $FFN(x) = \max{(0, xW_1+b_1)}W_2+b_2$