An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
2023-10-03
Keywords: #ViT
3. Method
3.1 Vision Transformer (ViT)
⚔️ Encoder Input
- Original Transformer: 1D sequence of token embeddings
- ViT: Reshape the image into a sequence of flattened 2D patches; $x\in \mathbb{R}^{H\times W \times C} \rightarrow x_p \in \mathbb{R}^{N\times (P^2 C)}$, and $N=HW/P^2$ is the resulting number of patches.
- Learnable Embedding: We prepend a learnable embedding to the sequence of embedded patches $(z_0^0=x_{\text{class}})$, whose state at the output of the Transformer encoder $(z_L^0)$ serves as the image representation $y$.
- Position Embedding: 1D position embeddings are added to the patch embeddings to retain positional information.
- Input = [Position + Patch] + [Learnable]
⚔️ Encoder
- Original Transformer, ViT: Alternating layers of multiheaded self-attention and MLP blocks. Layernorm (LN) is applied before every block, and residual connections after every block.
- ?? MLP contains two layers with a GELU non-linearity:
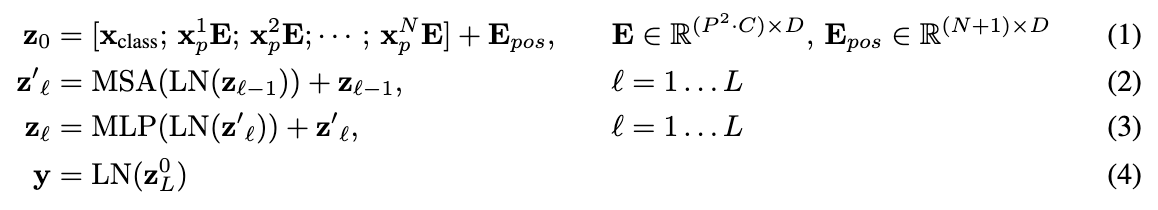
⚔️ Inductive bias
- What is induction bias? The assumptions a model makes to predict outputs. Models with strong inductive biases incorporate more assumptions about the structure of the data, which can lead to better performance on tasks that fit those assumptions.
- ViT has much less image-specific inductive bias than CNNs.
- Inductive bias of CNNs: locality, two-dimensional neighborhood structure, and translation equivariance
- Inductive bias of ViTs: Only MLP layers are local and transitionally equivariant, while self-attention layers are global.
- Two-dimensional neighborhood structure used only for: 1) image patching, and 2) position embedding adjustment
⚔️ Hybrid Architecture
- The input sequence can be formed from feature maps of a CNN.