EQ-Net: Elastic Quantization Neural Networks
2022.12.17
Keywords: #Quantization
0. Abstract
- github code: https://github.com/xuke225/EQ-Net
- Proposal: EQ-Net which aims to train a robust weight-sharing quantization supernet
- Elastic Quantization Space: Elastic bit-width, granularity, and symmetry → to adapt to various mainstream quantitative forms
- Weight Distribution Regularization Loss (WDR-Loss) and Group Progressive Guidance Loss (GPG-Loss) → to bridge the inconsistency of the distribution for weights and ouput logits in the elastic quantization space gap
- Conditional Quantization-Aware Accuracy Precision (CQAP) as an estimator to quickly search mixed-precision quantized NN in supernet.
1. Introduction
- Quantization incurs added noise due to reduced precision
- PTQ: Only requires access to a small calibration dataset → effectiveness declines when applied to low bit quantization (<= 4bits)
- QAT: By simulating the quantization operation during training or fine-tuning, the network can adapt to quantization noise → better than PTQ
- Problem: The forms of quantization supported by different hardware platforms are all different. (ex) NVIDIA’s GPU (channel-wise symmetric quantization in TensorRT inference engine), Qualcomm’s DSP (per-tensor asymmetric quantization in SNPE inference engine) → repeated optimization leads to low efficiency of model qunatization deployment
- Proposal
- Elastic Quantization Space: A unified quantization formula that integrates various model quantization forms and implementing elastic switching of 1) Quantization bit-width, 2) Quanization granularity 3) Quantization symmetry through parameter splitting
- WDR-Loss, GPG-Loss: Unlike NAS, EQ-Net is fully parameter-shared, and there is no additional weight parameter optimization space with network structure differences. → problem of negative gradient suppression(due to different quantization forms; samples with inconsistent predictions between quantization configurations) → WDR-Loss, GPG-Loss is an efficient training strategy for EQ-Net
- CQAP combined with a genetic algorithm: Specify any form in the elastic quantization space and quickly obtain a quantized model with the corresponding accuracy. (Can achieve both uniform and MPQ)
2. Related Work
- One-Shot Network Architecture Search
- Multi-Bit Quantization of Neural Networks
3. Approach
3.1 Quantization Preliminaries
- Quantization / Dequantization operation
3.2 Elastic Quantization Space Design
3.2.1 Elastic Quantization Bit-Width
- Separate and store the quantization step size and zero-point required for different quantization bit-widths.
- Higher bit-widths: Small quantization step size → Large saturation truncation range
- Lower bit-widths: Larger quantization step size → Small saturation truncation range → Alleviates training pressure for hyperparameters → Poses challenges to the robustness of shared weights.
3.2.2 Elastic Quantization Symmetry
- Symmetric quantization: Zero-point is fixed to 0 (z = 0)
- Asymmetric quantization: Zero-point is adjustable to different ranges (z ∈ Z).
- The switching between the two is achieved by dynamically modifying the value of the zero point.
3.2.1 Elastic Quantization Granularity
- Supports both per-tensor(one set of step size and zero-point for a tensor in one layer) and per-channel(quantizes each weight kernel independently) quantization.
- per-tensor > per-channel
- Step size and zero point for per-tensor can be obtained heuristically from per-channel, or can be learned as independent parameters
- EQG is for weights only, activation is are all in the form of per-tensor
3.3 Elastic Quantization Network Modeling
- Elastic quantization space of a model: $\varepsilon = \{\varepsilon_{b}, \varepsilon_{g}, \varepsilon_{s}\}$
- Training objective: Minimize the task loss under all elastic spaces elastic quantization spaces by optimizing the weights, step sizes, and zero points
3.4 Elastic Quantization Training
Weight Distribution Regularization
- DNN weights often conform to Gaussian or Laplace distributions
- Skewness regularization: Reducing skewness → enhance robustness of weights in elastic symmetry
- Kurtosis regularization: Reducing sharpness → enhance robustness of weights in elastic bit-width
Group Progressive Guidance
- There are many subnets with varying quantization configurations, resulting in many soft labels that the network can learn from.
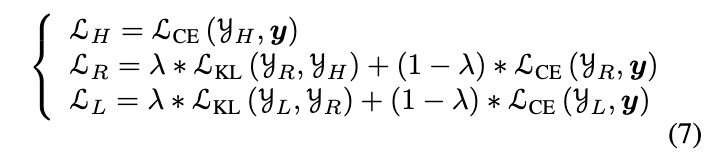
KLindicates the KL divergence loss andCEindicates the cross-entropy loss.- In the case of $\mathcal{L}_R$, the loss function acts as a regulation for two parts:
- $\mathcal{L}_{\text{KL}}(\mathcal{y}_R, \mathcal{y}_H)$ - Matches the random subnet’s output distribution, and the highest quantization bit-width’s subnet’s output distribution.
- $\mathcal{L}_{\text{CE}}(\mathcal{y}_R, \mathcal{y})$ - The loss between the random subnet’s output and the original model’s output.
4.3 Ablation Studies
Weight Distribution Regularization
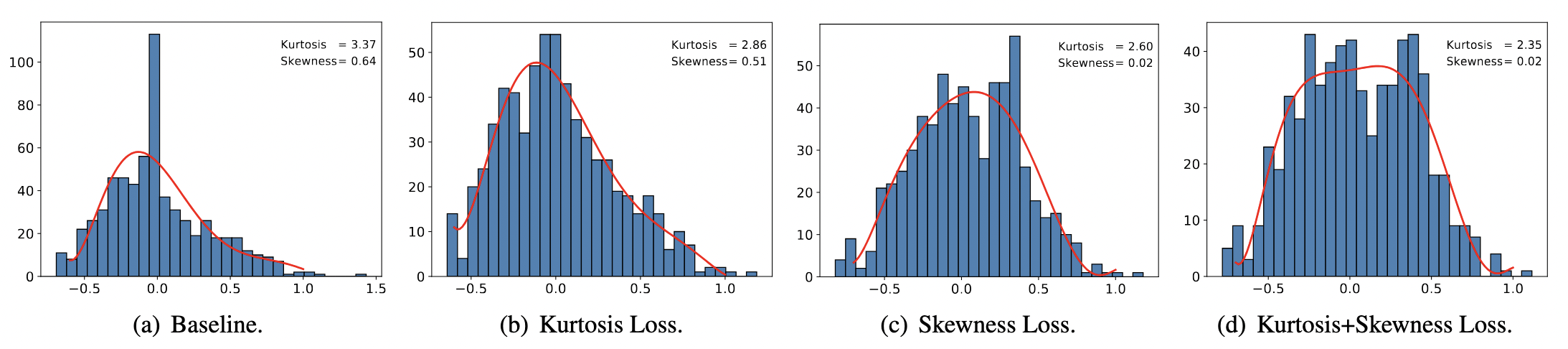
- The impact of skewness and sharpness of weight distribution on fixed bit-width quantization is relatively insignificant.
- However, for elastic quantization with high robustness demands, such phenomena can significantly affect the overall performance, particularly for low bit widths.
- Simultaneously applying kurtosis and skewness regularization can lead to a distribution effect that is closer to uniform distribution, eliminating data skewness and sharpness.
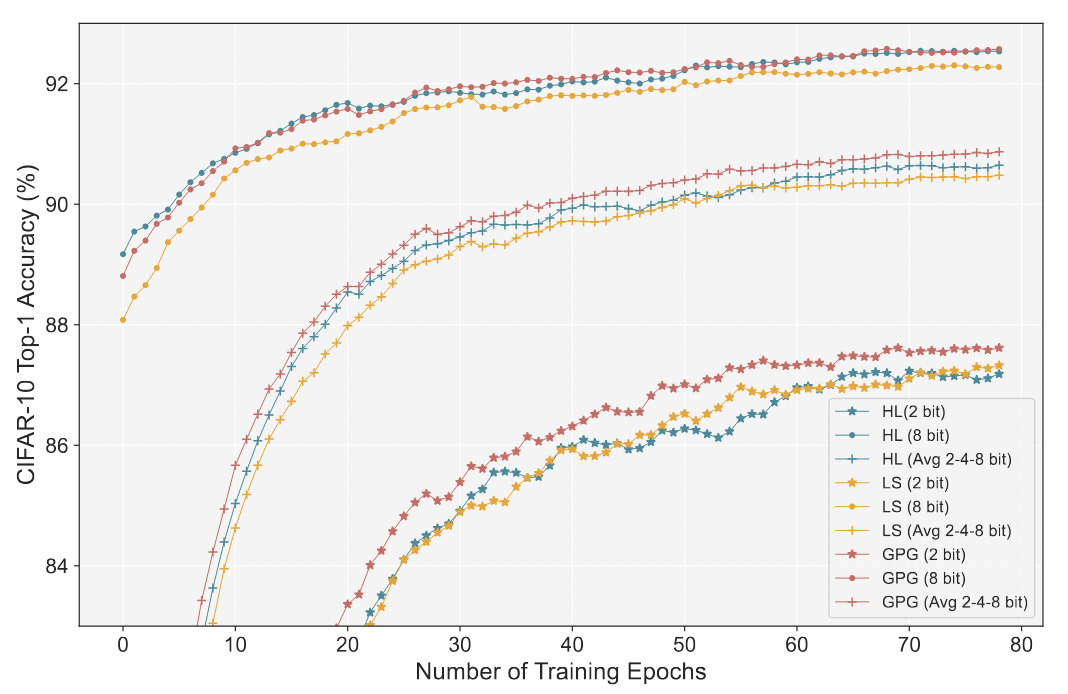
Effectiveness of Group Progressive Guidance (GPG)
- GPG utilizes soft labels from the high bit-width subnet to progressively guide the low bit-width subnet, creating more coherence between the output of the high and low bit-width networks.
- To demonstrate the training efficiency of the whole quantization supernet, we use the average precision of 2-4-8 bit-widths,and the average precision of our method is always the best.
- The Convergence Curve of ResNet20 trained using three different methods(hard label, label smoothing, and our GPG method).
5. Conclusion
- A one-shot weight-sharing quantization supernet.
- EQ-Net can support subnets with both uniform and mixed-precision quantization without retraining.
- Weight Distribution Regularization(WDR) and Group Progressive Guidance(GPG) techniques to optimize EQ-Net.