On-Device Training Under 256KB Memory
2024-01-20
Keywords: #Quantization
0. Abstract
- On-device training faces two unique challenges:
- The quantized graphs of neural networks are hard to optimize due to low bit-precision and the lack of normalization
- The limited hardware resource does not allow full back-propagation
1. Introduction
- On-device training allows us to adapt the pre-trained model to newly collected sensory data after deployment.
- Issue:
- Memory constraint (limited SRAM size)
- MCs are bare metal and do not have an OS
- Proposal:
- Quantization-Aware Scaling
- Sparse Update
- Tiny Training Engine
- Contribution:
- Our solution enables weight update not only for the classifier, but also for the backbone.
- Our system-algorithm co-design scheme reduces the memory footprint.
- Our framework greatly accelerates training
2. Approach
Preliminaries
- To keep the memory efficiency, we update the real quantized graph, and keep the update weights as $\text{int8}$
- The gradient computation is also performed in $\text{int8}$ for better computation efficiency.
- Real quantized graph vs Fake quantized graph: The fake quantization graph uses $\text{fp32}$, leading to no memory or computation savings. → Real quantized graphs are for efficiency, while fake quantized graphs are for simulation.
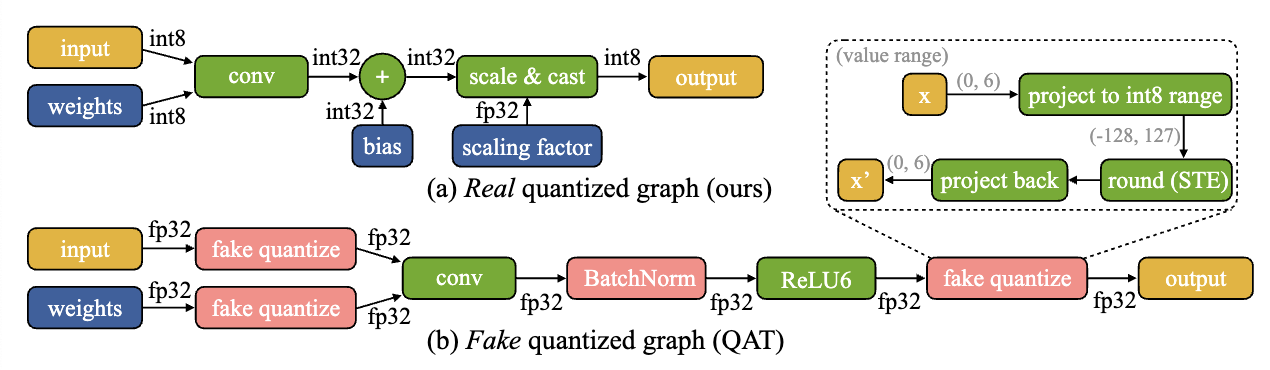
2.1 Optimizing Real Quantized Graphs
Training with a real quantized graph is difficult: the quantized graph has tensors of different bit-precisions ($\text{int8, int32, fp32}$) and lacks Batch Normalization layers → Unstable gradient update
Gradient scale mismatch.