Low-bit Quantization Needs Good Distribution
2024-04-16
Keywords: #Quantization #WeightDistribution
0. Abstract
- Uniform-like distributed weights and activations have been proved to be more friendly to quantization while preserving accuracy.
- Scale-Clip: A distribution reshaping technique that can reshape weights/activations into a uniform-like distribution in a dynamic manner.
- (A novel) Group-based Quantization algorithm: Different groups can learn different quantization parameters, which is merged into batch normalization layer.
- Group-based Distribution Reshaping Quantization (GDRQ) framework: Scale-Clip + Group-based Quantization algorithm
1. Introduction
-
QAT: Focus on minimizing the KL-divergence between the original weights and quantized weights when training.
-
Proposal: Optimize both the pre-trained model and the quantization bins together
- Theoretically analyze that uniformly-distributed pre-trained models result in less quantized-loss and is more friendly to linear quantization.
- Scale-clip technique
- Group-based quantization → Group-based Distribution Reshaping Quantization framework (GDRQ)
3. Method
- Model the linear quantization task as a quantized-loss optimization problem.
3.2. Good Distribution for Linear Quantization
- Quantization cause the quantized weights to have significant quantized-loss.
- Quantized Loss:
- The optimal $\alpha^\ast$ (clamping value):
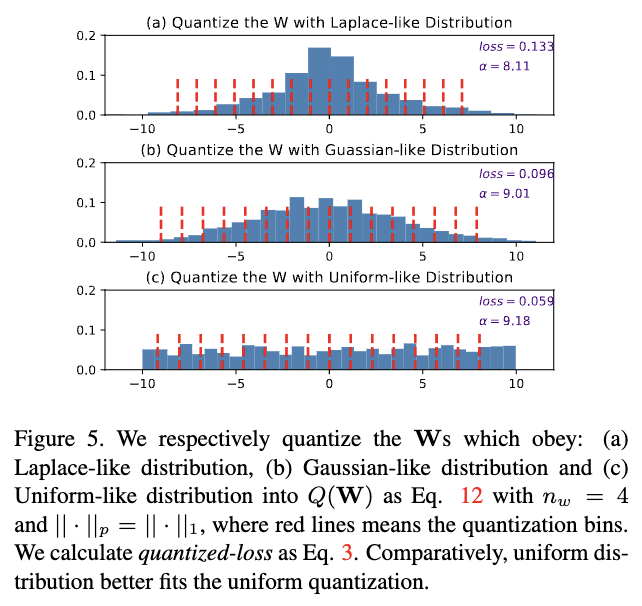
- Quantized Loss: Laplace > Gaussian > Uniform
- The optimal $\alpha^\ast$ (clamping value): Laplace < Gaussian < Uniform → The dynamic range is biggest for uniform distribution.
- We divide the quantized-loss optimization into two steps: 1) Optimizing the pre-trained model 2) Optimizing the quantization bins
3.3. Scale-Clip for Distribution Reshaping
-
Scale-Clip for weights
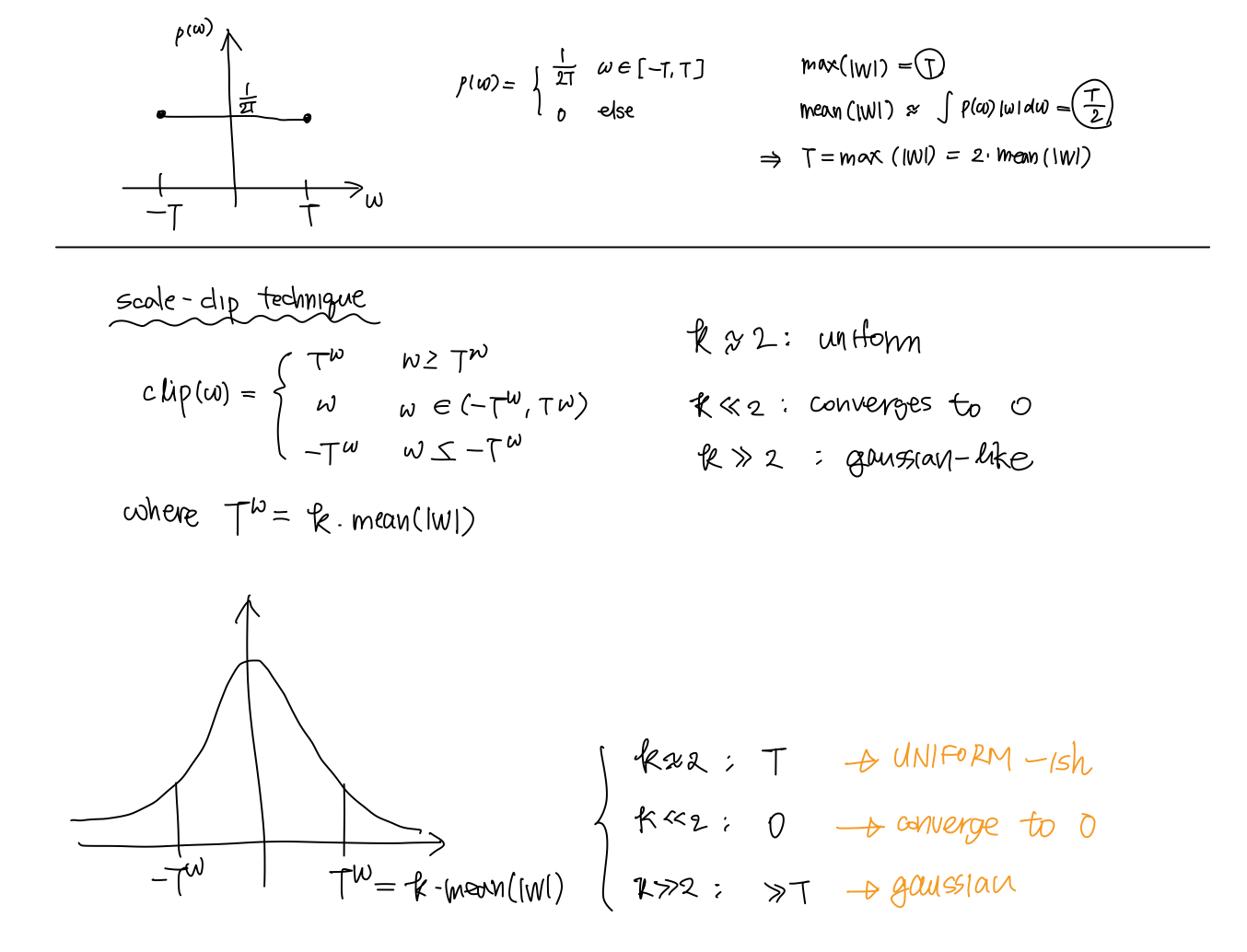
- Scale-Clip for activations
- The statistical measures of $\mathbf{A}$ are dependent on the data and unstable in the training process
- To handle this, a large $k$ should be chosen to adapt to the changeable statistical measures mean.
- Note that clipped method has already been widely used, such as gradient clipping, and activation clipping
3.4. Group-based Quantization
- To increase representative capacity of the low-bit model, we adopt group-based quantization
- Group-based quantization: Splits the $\mathbf{W}$ filters into several groups, and quantize the grouped filters to search different $\alpha$ and determine different quantization bins.