BigNAS: Neural Architecture Search with Big Single-Stage Models
2024-08-17
Keywords: #Activation #Batch Normalization
1. Introduction
- Recent efficient NAS methods are based on weight sharing. -> Reduce search costs by orders of magnitude.
- Train a super-network, and then identify a subset of its operations which gives the best accuracy while satisfying hardware constraints.
- General idea & advantage: The super-network can be used to rank candidate architectures.
- Problem: Accuracy predictions from supernets are much lower than models traine from scratch.
- Assumption 1: Retrain separate model for each device of interest. -> Incurs significant overhead.
- Assumption 2: Post-process weights after training is finished; progressive shrinking proposed by Once-for-All networks. -> This post-processing complicates the model training pipeline. Child models still require fine-tuning.
- Contribution
- Propose several techniques to bridge the gap between distinct initialization/learning dynamics across small & big child models w/ shared params.
- Train a single-stage model: a single model which we can directly slice high-quality child models w/o any extra post-processing.
- Difference from existing one-shot methods
- Much wider coverage of model capacities.
- All child models are trained in a way such that they simultaneously reach excellent performance at the end of the search phase.
- Main point: How to train a high-quality single-stage model?
3.1 Training a High-Quality Single-Stage Model
- Sandwich Rule (★ EQ-Net, MultiQuant)
- Sample the smallest child + biggest child + $N$ randomly sampled child -> Aggregates the gradients from all sampled child models before updating weights.
- Intuition: Improve all child models in the search space simultaneously, by pushing up both the performane lower/upper bound.
- Inplace Distillation
- Inplace Distillation: Takes the soft labels of biggest child to supervise all other child models.
- Comes for free in BigNAS training settings, due to sandwich rule.
- All child models are only trained with inplace distillation loss from start to end. -> The temperature hyper-parameter or the mixture of distillation/target loss are not used.
- Initialization (??)
- Training single-stage models worked when we reduced learning rate to 30% of its original value, but this leads to much worse results.
- Initialize the output of each residual block (before skip connection) to zero tensor by setting learnable parameter $\gamma = 0$ in the last BN layer. -> This ensures identical variance before and after residual block regardless of the fan-in.
- Also add a skip connection in each stage transition when either resolutions or channels differ (using 2x2 avg. pooling and/or 1x1 conv if necessary) to construct an identity mapping.
- Convergence Behavior
- In practice, big child models converge faster while small child models converge slower. (★)
- Dilemma: When performance of big child models peaks, small child models are not fully-trained. When small child models have better performance, the big child models already overfitted.
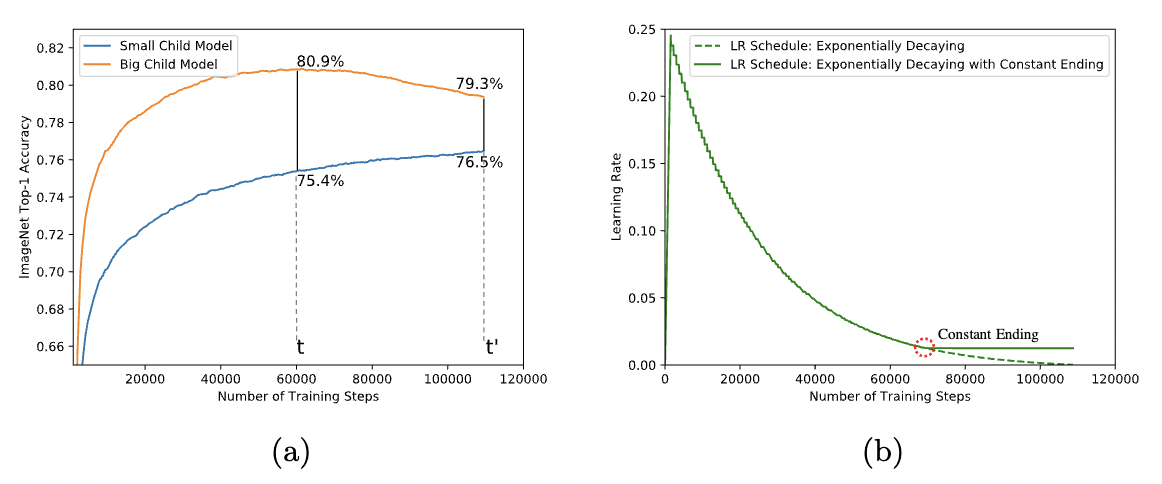
- Learning rate sceduler: Exponential decay -> Exponential decay with constant ending.
- Benefits
- With slightly larger lr at the end, the small child models learn faster.
- Constant lr at the end alleviates the overfitting of big child models as weights oscillate.
- Regularization
- Big child models tend to overfit, whereas small child models tend to underfit.
- General solutions: 1) Same weight decay to all child models, 2) Larger dropout for larger NNs.
- Problem: Single-stage models; interplay among the small and big child models w/ shared parameters.
- Solution: Regularize only the biggest child model (i.e., the only model that has direct access to the ground truth training labels) -> Apply this rule to both weight decay & dropout.
- Batch Norm Calibration
- After training, we re-calibrate BN stats. for each sampled child model for deployment.